Αναγνώριση κειμένου από φωτογραφίες ή σάιτς
Έχουμε βρεθεί πολλές φορές στη θέση να έχουμε ένα κείμενο στην οθόνη του υπολογιστή και να μη μπορούμε να το αντιγράψουμε για να το επικολλήσουμε κάπου. Ένα IBAN από φωτογραφία βιβλιαρίου που τραβήχτηκε με το κινητό και στάλθηκε με μέιλ, ένα κείμενο με οδηγίες από κάποιο βίντεο στο youtube, ένα απόσπασμα από κλειδωμένο ή «δύσκολο» pdf, κ.α.
Και βέβαια κάτι πολύ συνηθισμένο σε εκπαιδευτικούς, βοήθεια σε μαθήματα ή λύσεις ασκήσεων online, τα οποία είναι αδύνατο να κατεβούν ή να αντιγραφούν, για να τα χρησιμοποιήσει ο καθένας με το δικό του τρόπο. Γνωστές τέτοιου είδους περιπτώσεις, είναι οι δημοφιλείς ιστότοποι taexeiola και lisari, με λυσάρια και βοηθήματα όλων των μαθημάτων όλων των εκπαιδευτικών βαθμίδων, που χρησιμοποιούνται κατά κόρον από εκπαιδευτικούς και μαθητές. Αν και μας δίνουν το δικαίωμα να κάνουμε ανάγνωση όλου του υλικού, δεν επιτρέπουν να το αντιγράψουμε για να το χρησιμοποιήσουμε πάνω στα pdf των βιβλίων, με τον τρόπο που δείξαμε στο άρθρο μας Επεξεργασία pdf αρχείων στον υπολογιστή.
Η πιο συνηθισμένη ενέργεια που μπορούμε να κάνουμε, είναι βέβαια η πληκτρολόγηση του κειμένου που μας ενδιαφέρει. Αν θέλουμε όμως να αποφύγουμε την πληκτρολόγηση (και τα λάθη που μπορεί να προκύψουν) και να κερδίσουμε χρόνο, υπάρχει ένας εύκολος τρόπος για την αναγνώριση κειμένου από τέτοιου είδους σάιτς, φωτογραφίες, βίντεο, pdf και γενικά από οτιδήποτε εμφανίζεται στην οθόνη του υπολογιστή..
Αυτό το πετυχαίνουμε με τη χρήση του Capture2Text, ενός δωρεάν προγράμματος που μπορούμε να το κατεβάσουμε δωρεάν από εδώ. (Για τους νεώτερους υπολογιστές υπάρχει και έκδοση 64bit). Το Capture2Text είναι portable δηλαδή δεν χρειάζεται κάποιου είδους εγκατάσταση, απλώς αποσυμπιέζουμε το συμπιεσμένο zip αρχείο κι έχουμε το φάκελο Capture2Text, μέσα στον οποίο υπάρχουν τα αρχεία του προγράμματος. Για να αναγνωρίζει τα ελληνικά θα πρέπει να κατεβάσουμε το Greek.zip, να το αποσυμπιέσουμε και να τοποθετήσουμε το αρχείο ell.traineddata μέσα στον υποφάκελλο tessdata.
Κάνοντας διπλό κλικ στο Capture2Text που βρίσκεται μέσα στο φάκελο, το πρόγραμμα αρχίζει να τρέχει και να είναι έτοιμο για την αναγνώριση κειμένου.
Κάνουμε δεξί κλικ στο εικονίδιο του προγράμματος (κάτω δεξιά στην taskbar των Windows). Από την επιλογή OCR Language επιλέγουμε τη γλώσσα που θέλουμε να αναγνωριστεί. Μετά ανοίγουμε τις Ρυθμίσεις (Settings) και από την πρώτη καρτέλα Hotkeys και από την πρώτη σειρά Start OCR Capture. μπορούμε να επιλέξουμε (και να θυμόμαστε) το συνδυασμό πλήκτρων που θα ενεργοποιούν την αναγνώριση κειμένου.

Απαραίτητη προϋπόθεση για να γίνει σωστά η αναγνώριση κειμένου από φωτογραφία ή σκαναρισμένο έγγραφο είναι, αυτά να είναι καθαρά, χωρίς θολά σημεία ή σκουπίδια.
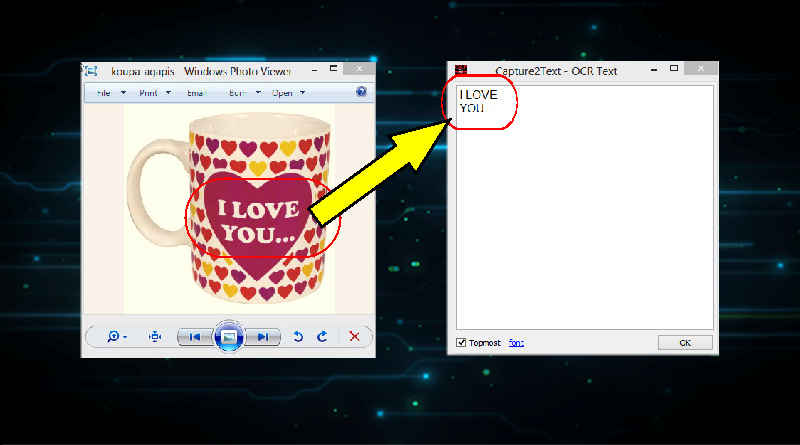
Κάθε φορά που θέλουμε να αντιγράψουμε κείμενο από φωτογραφία, βίντεο κ.α. τοποθετούμε τον κέρσορα πάνω και αριστερά από το κείμενο προς επιλογή, πατάμε το συνδυασμό πλήκτρων και σέρνουμε (χωρίς να κάνουμε κλικ) ως κάτω δεξιά. Όταν επιλεγεί όλο το κείμενο κάνουμε κλικ και σε λίγο ανοίγει ένα παράθυρο με έτοιμο το κείμενό μας, για διόρθωση και αντιγραφή.
Δείτε την παραπάνω διαδικασία σε βίντεο:
Το Capture2Text δεν συνιστάται για μεγάλα κείμενα, πολλών σελίδων όπου χρειάζεται ταχύτητα και ακρίβεια. Για το σκοπό αυτό υπάρχουν πολύ πιο εξειδικευμένα (και όχι δωρεάν) προγράμματα αναγνώρισης κειμένου.



Καλημέρα και Χρόνια Πολλά.
Θα ήθελα να σας παρακαλέσω να μου πείτε πως μπορώ να αντιγράψω μια μικρή φράση πέντε λέξεων, πάνω σε μια φωτογραφία με επικόλληση και όχι να την γράψω με τον απλό τρόπο που γράφουμε πάνω σε μια φωτογραφία.
Αυτό επειδή έχω πολλές φωτογραφίες και θα ήθελα να αντιγράψω σε όλες μια Χριστουγεννιάτικη ευχή.
Σας ευχαριστώ και σας εύχομαι ο καινούργιος χρόνος να σας με υγεία και ευτυχία.